Java metaprograming
WikiPedia 上对元编程的定义是:
元编程(英语:Metaprogramming),又译超编程,是指某类计算机程序的编写,这类计算机程序编写或者操纵其它程序(或者自身)作为它们的资料,或者在运行时完成部分本应在编译时完成的工作。多数情况下,与手工编写全部代码相比,程序员可以获得更高的工作效率,或者给与程序更大的灵活度去处理新的情形而无需重新编译。
编写元程序的语言称之为元语言。被操纵的程序的语言称之为“目标语言”。一门编程语言同时也是自身的元语言的能力称之为“反射”或者“自反”。
元编程工具主要有以下几种:
- 代码(.java)生成器(处理器)。
- 字节码(.class)增强(转换)。
- 运行时反射。
1 代码生成器
代码生成器是分析源代码生成新的代码的工具。
Spoon 就是代码生成器的一种(也可以用作运行时反射接口的替代品)。
另外一种被广泛的使用工具是 Pluggable Annotation Processing API,著名的 lombok 就是基于此实现。「 Pluggable Annotation Processing API」为 JSR269 规范的内容,在 JDK6 中被引入,意在代替 JDK5 引入的 APT「Annotation Processing Tool」。Javac 编译过程如下:

- javac对源代码进行分析,生成一棵抽象语法树(AST)
- 运行过程中调用实现了”JSR 269 API”的A程序
- 此时A程序就可以完成它自己的逻辑,包括修改第一步骤得到的抽象语法树(AST)
- javac使用修改后的抽象语法树(AST)生成字节码文件
使用例子:
- lombok。
- Spoon(还有其它功能)。
1.1 Annotation Processing
Annotatin Processing 扩展一般用来:
- 基于注解输出信息。如基于注解扫描输出警告信息到控制台,输出注解的统计信息到文件等。
- 基于注解生成代码。如注解在接口上自动生成接口的实现等。
I) 详细介绍
如下是 javac 文档中 annotation processing 部分的说明:
ANNOTATION PROCESSING
javac provides direct support for annotation processing, superseding the need for the separate annotation processing tool, apt.The API for annotation processors is defined in the javax.annotation.processing and javax.lang.model packages and subpackages.
Overview of annotation processing
Unless annotation processing is disabled with the -proc:none option, the compiler searches for any annotation processors that are available. The search path can be specified with the -processorpath option; if it is not given, the user class path is used. Processors are located by means of service provider-configuration files named META-INF/services/javax.annotation.processing.Processor on the search path. Such files should contain the names of any annotation processors to be used, listed one per line. Alternatively, processors can be specified explicitly, using the -processor option.After scanning the source files and classes on the command line to determine what annotations are present, the compiler queries the processors to determine what annotations they process. When a match is found, the processor will be invoked. A processor may “claim” the annotations it processes, in which case no further attempt is made to find any processors for those annotations. Once all annotations have been claimed, the compiler does not look for additional processors.
If any processors generate any new source files, another round of annotation processing will occur: any newly generated source files will be scanned, and the annotations processed as before. Any processors invoked on previous rounds will also be invoked on all subsequent rounds. This continues until no new source files are generated.
After a round occurs where no new source files are generated, the annotation processors will be invoked one last time, to give them a chance to complete any work they may need to do. Finally, unless the -proc:only option is used, the compiler will compile the original and all the generated source files.
注解处理器是 javac(Java programming language compiler) 提供的注解处理支持功能。替代之前的 apt(annotaion processing tool) 功能。
启动与禁止
默认注解处理器是开启的,可以通过 -proc:none 参数 disable。如果不指定注解处理器扫描路径(通过 -processorpath 参数指定),默认会收集 classpath 下所有的处理器,收集逻辑与 SPI 逻辑一致,处理器实现类在 META-INF/services/javax.annotation.processing.Processor 文件中指定。javac 还允许使用 -processor 参数显式执行使用的处理器。
处理逻辑(round)
javac 扫描源文件和 class 文件找到所有存在的注解,并查找对应的注解处理器,并调用相应逻辑。如果处理器生成了新的源文件,那么会触发下一轮的注解处理,此轮的处理集为上轮生成的或改变的文件。
II) 编程实践
处理器扩展的核心类为 Processor。
Processor 流程
Annotation processing happens in a sequence of rounds. On each round, a processor may be asked to process a subset of the annotations found on the source and class files produced by a prior round. The inputs to the first round of processing are the initial inputs to a run of the tool; these initial inputs can be regarded as the output of a virtual zeroth round of processing. If a processor was asked to process on a given round, it will be asked to process on subsequent rounds, including the last round, even if there are no annotations for it to process. The tool infrastructure may also ask a processor to process files generated implicitly by the tool’s operation.javac 对 Processor 的调用流程
Each implementation of a Processor must provide a public no-argument constructor to be used by tools to instantiate the processor. The tool infrastructure will interact with classes implementing this interface as follows:
- If an existing Processor object is not being used, to create an instance of a processor the tool calls the no-arg constructor of the processor class.
- Next, the tool calls the init method with an appropriate ProcessingEnvironment.
- Afterwards, the tool calls getSupportedAnnotationTypes, getSupportedOptions, and getSupportedSourceVersion. These methods are only called once per run, not on each round.
- As appropriate, the tool calls the process method on the Processor object; a new Processor object is not created for each round. If a processor object is created and used without the above protocol being followed, then the processor’s behavior is not defined by this interface specification.
The tool uses a discovery process to find annotation processors and decide whether or not they should be run. By configuring the tool, the set of potential processors can be controlled. For example, for a JavaCompiler the list of candidate processors to run can be set directly or controlled by a search path used for a service-style lookup. Other tool implementations may have different configuration mechanisms, such as command line options; for details, refer to the particular tool’s documentation. Which processors the tool asks to run is a function of what annotations are present on the root elements, what annotation types a processor processes, and whether or not a processor claims the annotations it processes. A processor will be asked to process a subset of the annotation types it supports, possibly an empty set. For a given round, the tool computes the set of annotation types on the root elements. If there is at least one annotation type present, as processors claim annotation types, they are removed from the set of unmatched annotations. When the set is empty or no more processors are available, the round has run to completion. If there are no annotation types present, annotation processing still occurs but only universal processors which support processing “*” can claim the (empty) set of annotation types.
Note that if a processor supports “*” and returns true, all annotations are claimed. Therefore, a universal processor being used to, for example, implement additional validity checks should return false so as to not prevent other such checkers from being able to run.
If a processor throws an uncaught exception, the tool may cease other active annotation processors. If a processor raises an error, the current round will run to completion and the subsequent round will indicate an error was raised. Since annotation processors are run in a cooperative environment, a processor should throw an uncaught exception only in situations where no error recovery or reporting is feasible.
The tool environment is not required to support annotation processors that access environmental resources, either per round or cross-round, in a multi-threaded fashion.
If the methods that return configuration information about the annotation processor return null, return other invalid input, or throw an exception, the tool infrastructure must treat this as an error condition.
Processor 最佳实践建议
To be robust when running in different tool implementations, an annotation processor should have the following properties:The result of processing a given input is not a function of the presence or absence of other inputs (orthogonality). Processing the same input produces the same output (consistency)(函数式). Processing input A followed by processing input B is equivalent to processing B then A (commutativity) Processing an input does not rely on the presence of the output of other annotation processors (independence)
The Filer interface discusses restrictions on how processors can operate on files.
Note that implementors of this interface may find it convenient to extend AbstractProcessor rather than implementing this interface directly.
III) 参考
- ANNOTATION PROCESSING 101 - 一个可作为模板的编程实例;对 Processor 中会使用到的 Elements和TypeMirrors 有说明。
- Lombok原理分析与功能实现 - 在类中增加代码。
- JCTree - 代码生成可简单分为两种:在当前类中增加;直接生成另外的类。后者比较简单,可以使用封装好的 poet 库。前者只能借助 JCTree 接口来完成,但是可供参考的资料很少,lombok就是使用 JCTree 完成代码生成。
- 另一个例子 - JCTree API
- 一个不错的PPT介绍 - 包含可用的代码生成库以及基于注解处理器扩展库的信息;包含编程 API 的解释,如 Element 相关、ElementFilter 相关。
IV) 总结
Annotation Processing 编程的核心点在于:
- ProcessingEnvironment。从 ProcessingEnvironment 获取的工具类,包含 trees(从 Element 转换为 JCTree), names, treeMaker(生成 JCTree), messger(编译过程消息输出)。
- Element。Annotation Proccsor 层面的代码块抽象类,编译器扫描代码生成的都是 Element。根据 RoundEnvironment 接口获取所有带有某个注解的元素获取到的就是 Element,Element实现可能是 TypeElement(接口或者类)、VariableElement(变量)等。Element 提供代码块的基本信息API,但涉及到代码块的详细遍历修改还是需要使用 JCTree,JCtree 到 Element 之间的准换使用的就是在 1 中所述的 trees API。
- JCTree/TreeMaker。Annotation Processor 的类都在 javax.annotation.processing and javax.lang.model 下,而 JCTree 是 java tools 包
com.sun.tools提供,用于代码扫描、解析、修改能力。
2 反射
如 WikiPedia 中对元编程的定义一样,所谓的反射就是 语言自己编写自己代码 的过程。
通过反射,可以获取到类内部属性、方法等信息。同时可以实例新的类,如「动态代理」。
关于代理模式以及动态代理,可见 代理模式原理及实例讲解。
使用例子:
- Spring AOP 中基于JDK代理的实现就是这种方式(使用限制为需要时接口类)。
- Junit/TestNG 使用反射来处理注解。
3 字节码增强
和 2.1 中的生成代码不一样,字节码工具是分析并修改/生成字节码的工具。如 Spring AOP 中,如果对象类没有实现接口,那么会使用 CGlib,通过继承对象类进行动态代理。
使用例子:
- Javassist。
- ASM。基于 ASM 的 CGLIB 等。
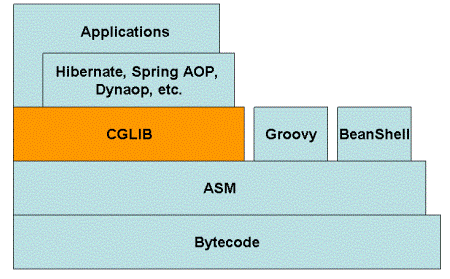
3 总结
如上所说的三种形式(代码生成,字节码增强,反射)可以在不同阶段(编译期、运行期)做元编程的实现工具。Java 注解为元编程的形式之一,上述方式同样适用于注解的实现。
参考: